
Face Detection using Web Cam in Python
Face Detection has become extremely easy in 2018 thanks to great strides made in computer vision and deep learning. Many open source libraries such as OpenCV and Dlib now provide pretrained models for face detection. There are also plenty of Paid (and free) services out there that provide pre-trained neural networks for the task of face detection and analysis. You only need basic programming skills to use their API.
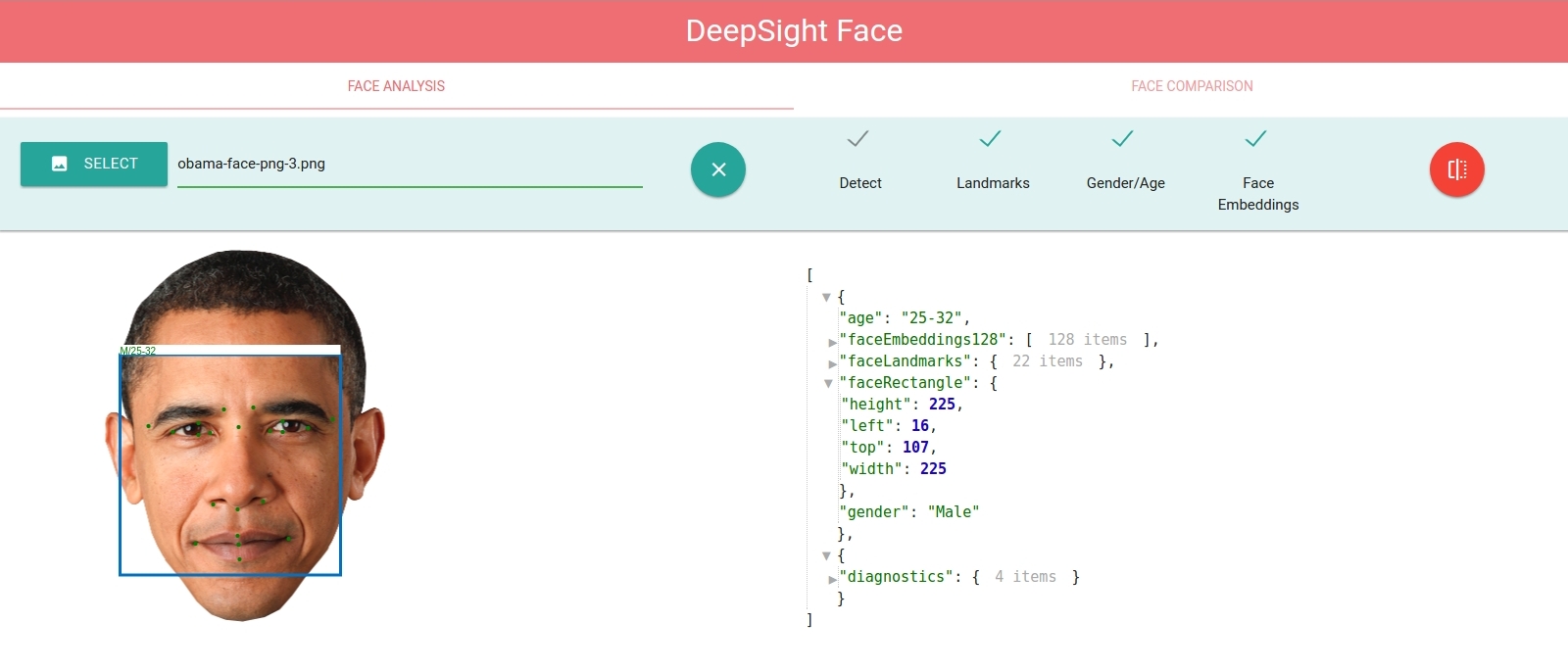
This post covers using our product – Deepsight Image Recognition SDK for face detection. Deepsight encapsulates pre-trained neural networks and makes them accessible through a RESTful API. You can see a comparison between our SDK and OpenCV’s face detector here. Our face detector will also be able to determine gender, age and facial landmarks.
Installation
If you haven’t already, then the first step would be to install Deepsight. The documentation covers this topic quite well, so, it is highly recommended that you follow that. After you have launched Deepsight and it starts running you can follow what comes next.
Next, install Python and dependencies. Follow this in the documentation. Once you have python and pip ready, you should install opencv.
You could either build from sources (follow the guides for Windows and Linux) or install from pip wheels
[bash]
pip install opencv-python
[/bash]
Writing Python Code
Create a file face.py with the following code
[python]
import cv2
import requests
import numpy as np
import json
import argparse
import signal
import logging
import datetime, time
import os
# parse arguments
parser = argparse.ArgumentParser(description=’Face Detection using webcam’)
parser.add_argument(‘–src’, action=’store’, default=0, nargs=’?’, help=’Set video source; default is usb webcam’)
parser.add_argument(‘–w’, action=’store’, default=320, nargs=’?’, help=’Set video width’)
parser.add_argument(‘–h’, action=’store’, default=240, nargs=’?’, help=’Set video height’)
parser.add_argument(‘–det’, action=’store’, default=’yolo’, nargs=’?’, help=’Select detector’)
parser.add_argument(‘–dbl’, action=’store’, default=0, nargs=’?’, help=’Double size’)
parser.add_argument(‘–exp’, action=’store’, default=0.1, nargs=’?’, help=’ExpandBy’)
args = parser.parse_args()
face_api = "http://127.0.0.1:5000/inferImage?returnFaceAttributes=true&returnFaceLandmarks=true&detector=%s&dblScale=%s&expandBy=%f"%(args.det,args.dbl,args.exp)
inp_w = int(args.w)
inp_h = int(args.h)
# start the camera
cap = cv2.VideoCapture(args.src)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, float(args.w))
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, float(args.h))
ret, frame = cap.read()
# catch exit signal
def signal_handler(signal, frame):
exit(0)
signal.signal(signal.SIGINT, signal_handler)
while True:
_, framex = cap.read()
key = cv2.waitKey(1) & 0xFF
frame = cv2.resize(framex, (int(args.w),int(args.h)))
r, imgbuf = cv2.imencode(".bmp", frame)
image = {‘pic’:bytearray(imgbuf)}
# perform api request
r = requests.post(face_api, files=image)
result = r.json()
if len(result) > 1:
faces = result[:-1]
diag = result[-1][‘diagnostics’]
for face in faces:
rect, gender, age, lmk = [face[i] for i in [‘faceRectangle’, ‘gender’, ‘age’, ‘faceLandmarks’]]
x,y,w,h, confidence = [rect[i] for i in [‘left’, ‘top’, ‘width’, ‘height’, ‘confidence’]]
# set threshold on detection confidence
if confidence < 0.6:
continue
# sometimes lmk points may be corrupt
for pt in range(1,69):
lx,ly = lmk[str(pt)]["x"], lmk[str(pt)]["y"]
if (int(lx) > 4850000000) or (int(lx) < 0):
lx = 1
if (int(ly) > 4850000000) or (int(ly) < 0):
ly = 1
cv2.circle(frame,(lx,ly),1,(255,255,255),-1,8)
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,255),4,8)
cv2.rectangle(frame, (x,y+h-10), (x+w,y+h), (255,0,255), -1, 8)
cv2.putText(frame, "%0.2f" % (confidence), (x, y+h-2), cv2.FONT_HERSHEY_COMPLEX_SMALL, 0.5, (255, 255, 255),1)
cv2.putText(frame, "%s"%(gender[0]), (x+w-10,y+h-2), cv2.FONT_HERSHEY_COMPLEX_SMALL, 0.5, (255,255,255),1)
cv2.imshow("frame", frame)
if key == ord(‘q’):
break
if key == ord(‘s’):
cv2.imwrite(‘screen%d.jpg’%count, frame)
cap.release()
print("Exit")
[/python]
Run the application using
[bash]
python face.py
[/bash]

You can try passing a video file with --src arg param.
Deepsight comes bundled with 4 face detectors
- MMOD Detector – This is based on sliding window. It is accurate but slow
- YOLO Detector – This is based on the famous You Only Look Once algorithm. It is fast but there are some false positives.
- YOLOHD Detector – This can detect smaller faces that YOLO misses
- HOG Detector – This is based on the classic Histogram of Oriented Gradients feature.
To select a particular detector, try
[bash]
python face.py –det mmod
python face.py –det yolo
python face.py –det yolohd
python face.py –det hog
[/bash]
Improving Performance of Gender/Age Classification
To improve the performance of gender/age classifiers and landmark detection, you can try increasing the bounding box size. Internally, the SDK crops the faces along the bounding boxes and performs inference on these crops. The size of these crops affect the accuracy of the inference as it determines the area of face being covered. Deepsight provides an api parameter called expandBy indicating the percentage by which to expand the raw detection boxes. For instance, expandBy=0.1 will expand the detection boxes by 10% on all sides (right, left, top, bottom). The following will expand the bounding boxes on all sides by 25%
[bash]
python face.py –det yolo –exp 0.25
[/bash]
The exact value that will work well for you depends on the image characteristics. Experiment with them.
This concludes our post. Feel free to comment your queries/doubts and I will try to get to them.