

Facial recognition technology is on the rise and has already made its way into every aspect of our lives. From smartphones, to retail, to offices, to parks… it is everywhere. If you are just getting started with computer vision, then face recognition is a must do project for you. Here in this guide, I seek to present all the existing facial recognition algorithms and how they work. We will explore classical techniques like LBPH, EigenFaces, Fischerfaces as well as Deep Learning techniques such as FaceNet and DeepFace.
As a continuation of the previous article, we will focus on the contribution made by Deep Learning in the approach to recognizing faces.
FaceNet
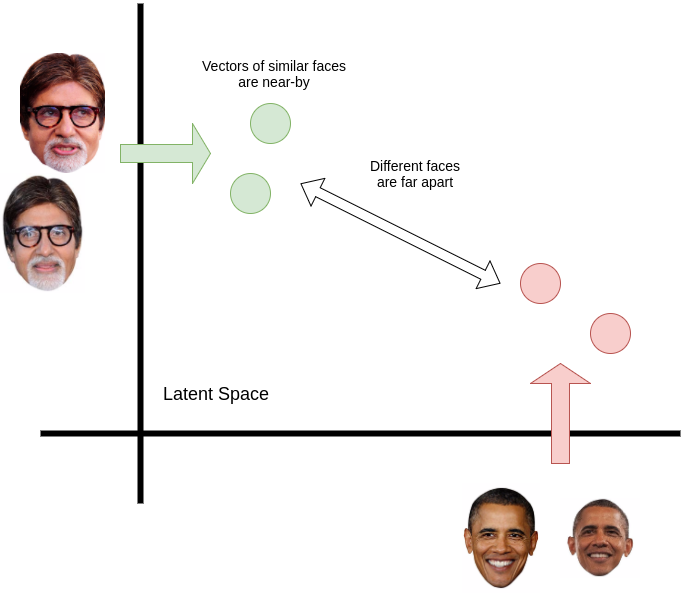
A revolutionary paper that made significant advances in face recognition accuracy was FaceNet published by researchers at Google. The authors introduced a new technique of projecting the pixel data of the face onto a latent space. The nature of the latent variables is such that same faces would be closer to each other whereas different faces would be far apart. They used convolutional neural networks to achieve this.
NNs are Universal Function Approximaters. They can be trained to learn anything. The challenge is to formulate a loss function appropriate to the problem at hand. The NN can then be trained to minimize this loss function using gradient descent.
The innovation in this paper was that of the Triplet Loss Function. This was a clever idea which paved the way for applied DL in solving a variety of other similarity measurement problems.
Triplet Loss
In typical classification tasks, there are a fixed number of classes and the network is trained using the softmax cross entropy loss. In the problem of face recognition however, we need to be able to compare two unknown faces and say whether they are from the same person or not. This is not feasible with softmax. We can’t train a giant classifier model for every face in existence!
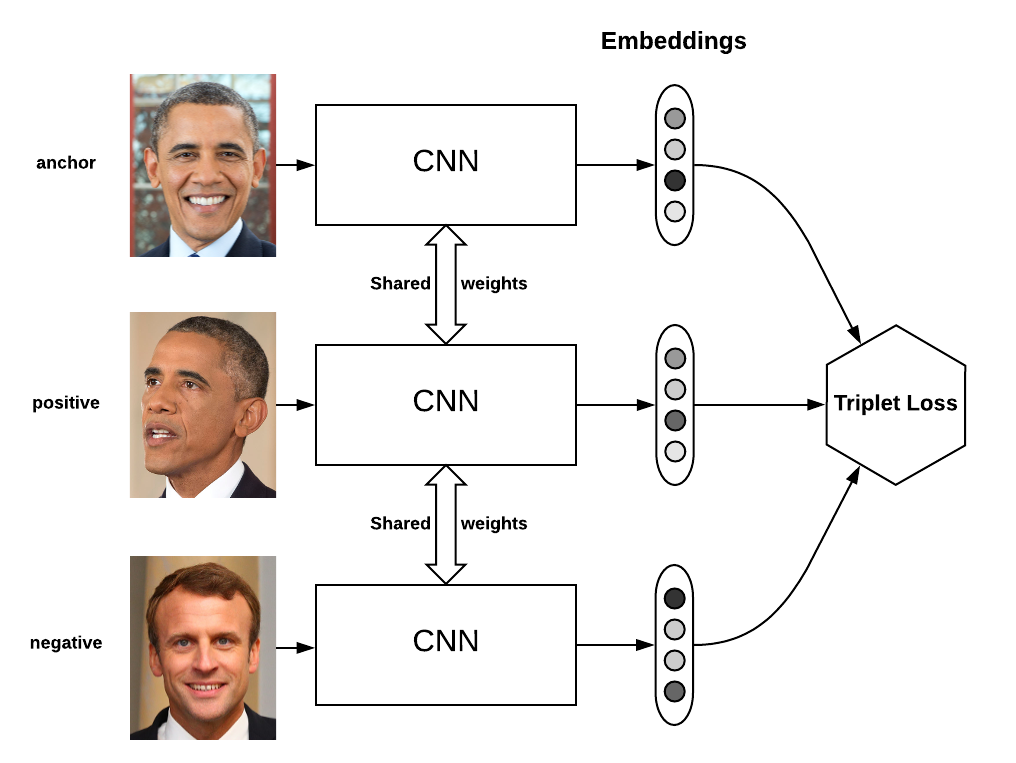
Triplet loss in this case is a way to learn good vector representation or embeddings (latent variables) for each face. In the embedding space, faces from the same person should be close together and form well separated clusters. This allows us to compare faces that the network has never seen before. The following is a quick summary of an excellent blog article written by Oliver here.
Definition of the loss
- Two faces with the same label have their embeddings close together in the embedding space
- Two faces with different labels have their embeddings far away.
The loss is defined over triplets of embeddings:
- an anchor a
- a positive p of the same class as the anchor
- a negative n of a different class
For some distance on the embedding space , the loss of a triplet is:
![]()
We minimize this loss, which pushes to and to be greater than . As soon as becomes an “easy negative”, the loss becomes zero.
Based on the definition of the loss, there are three categories of triplets:
- easy triplets: triplets which have a loss of , d(a,p)+margin<d(a,n)
- hard triplets: triplets where the negative is closer to the anchor than the positive, i.e.
- semi-hard triplets: triplets where the negative is not closer to the anchor than the positive, but which still have positive loss:
Each of these definitions depend on where the negative is, relatively to the anchor and positive. We can therefore extend these three categories to the negatives: hard negatives, semi-hard negatives or easy negatives.
The figure below shows the three corresponding regions of the embedding space for the negative.
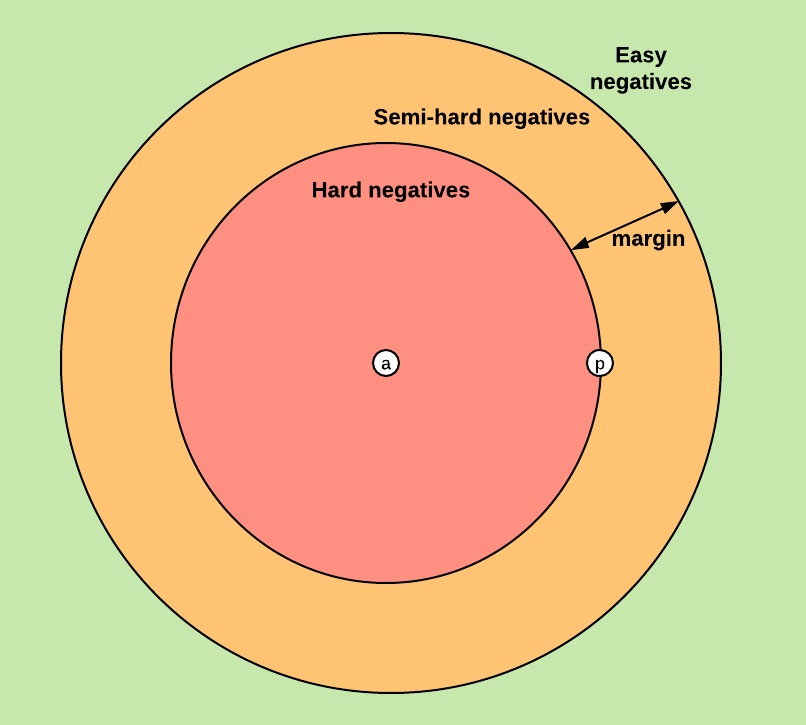
Choosing what kind of triplets we want to train on will greatly impact our metrics. In the original Facenet paper, they pick a random semi-hard negative for every pair of anchor and positive, and train on these triplets.
After the network is trained, it acts as an encoder that takes in pixel data and generates embeddings. A similar network trained on MNIST data generates embeddings that form clusters as shown below
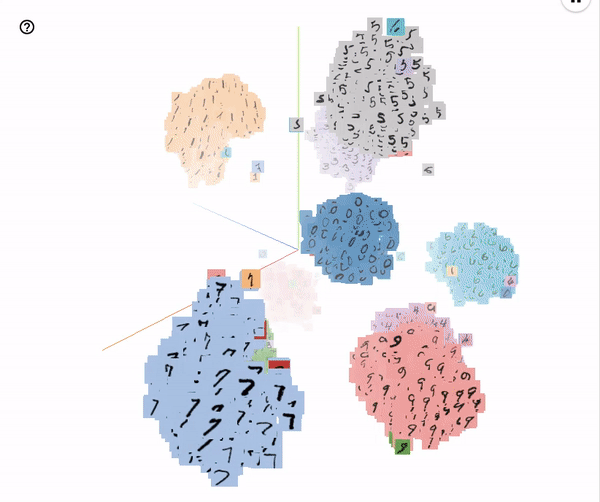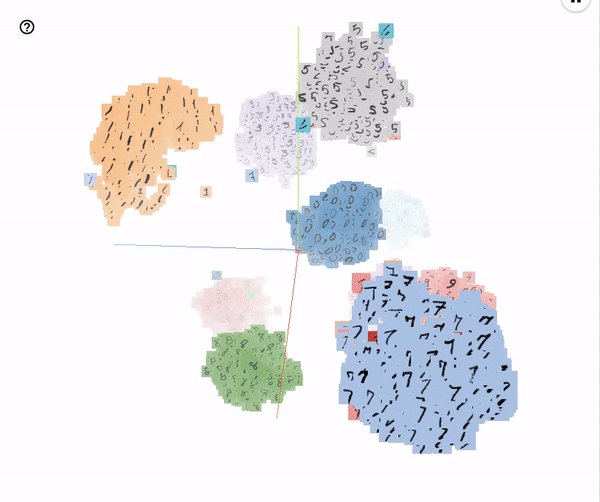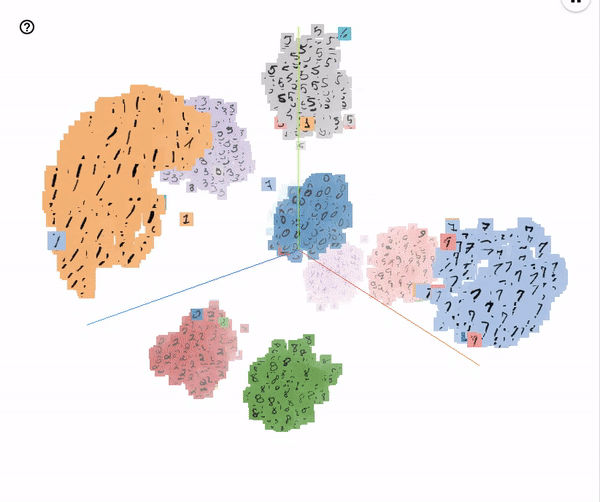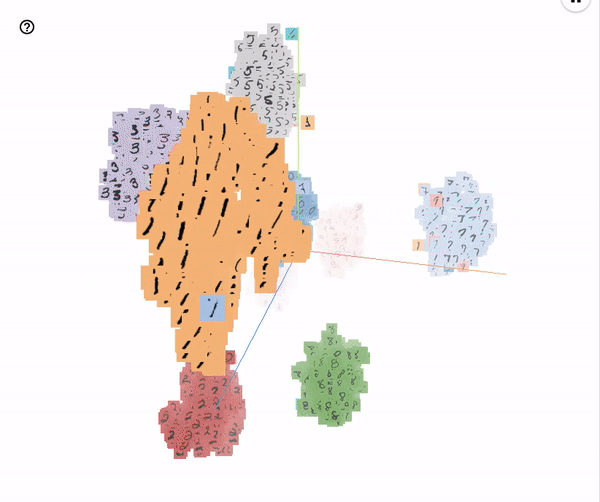
A new character can be identified by projecting it to this embedding space and finding the nearest cluster.
Conclusion
This is how Deep Learning based face recognition systems work. The embeddings generated by the CNNs are stored in a database. When a new face has to be searched, its embedding is generated and this embedding space is searched for the nearest point. If the nearest point is closer than a threshold, the face is found and associated metadata is retrieved from another DB to identify the individual. This article fairly summarises Deep Learning approach to face recognition. After FaceNet, many papers have been published in this domain using DL and some of them have surpassed human level accuracy.
Covering them is outside our scope. I hope this was an interesting read. Let us know your thoughts in the comments.
Reference:
- FaceNet Paper: https://arxiv.org/abs/1503.03832
- Triplet loss blog by Olivier Moindrot: https://omoindrot.github.io/triplet-loss