
Facial recognition is becoming increasingly inevitable as the globe becomes more and interconnected. With digitization penetrating our identities, it will soon be time to do away with passwords and PINs. Biometric devices are everywhere. From airports and offices to even our smartphones and computers. Facial recognition is the latest and greatest in this field and its rise alongside AI is sure to change our lives. The Markets And Markets research which was published recently, estimates that the facial recognition market is set to be worth $6.84 billion by 2021 from the current $3.35 billion in 2016. That’s essentially a doubling in size within a span of 5 years. The top drivers for this rapid growth will be Video Analytics, Public sector deployment (surveillance systems) and industrial sector applications.
Although the exact operation of commercial face recognition systems are a trade secret, they basically work by trying to extract key facial features such as distance between eye pupils, nose width, lip size etc. and encoding them in a template file. This is called feature engineering - as the features are handpicked.

facial landmark (courtesy: researchgate)
At the time of matching, these template files are compared and the identity of the individual is established. The downside to these techniques is the lack of accuracy. Extracting facial features is highly sensitive to the person’s mood (facial muscle variations), lighting and pose. Moreover, users of the system need to go through a rigid set of motions in order to make the system work reliably. In many implementations, this offsets the convenience. The whole point of facial recognition over other biometrics such as fingerprints was to give the user a seamless experience. Despite these downsides, unfortunately, many commercial solutions including those claiming to use 3D face matching etc, are based on these techniques.
However, recent strides made in the field of AI have led to the innovation of a new and much more accurate facial recognition system powered by Deep Learning. Instead of detecting facial landmarks such as eyes, nose etc. and constructing a template, these techniques emulate the human visual cortex and try to recognize faces the way humans do!
Our current understanding of the visual cortex is that, crudely, a layer of neurons receives visual stimuli from the eyes and passes this to subsequent layers. At each layer, the signal is modulated by a weight and, based on a threshold, used to activate the next layer. This process continues for thousands of layers until it reaches regions of the brain where it activates parts related to cognition. Hence, modern deep learning techniques try to emulate this behaviour using high performance computers.
A neural network with hundreds of layers is trained on a million faces. It is designed to output a 128 Dimensional vector from the pixel data of a person. Since the neural network is trained, it learns the necessary features it requires to distinguish faces all by itself. Hence, the performance is vastly superior to the hand picked features of the traditional technique. This allows the network to be robust to face pose, lighting and mood.
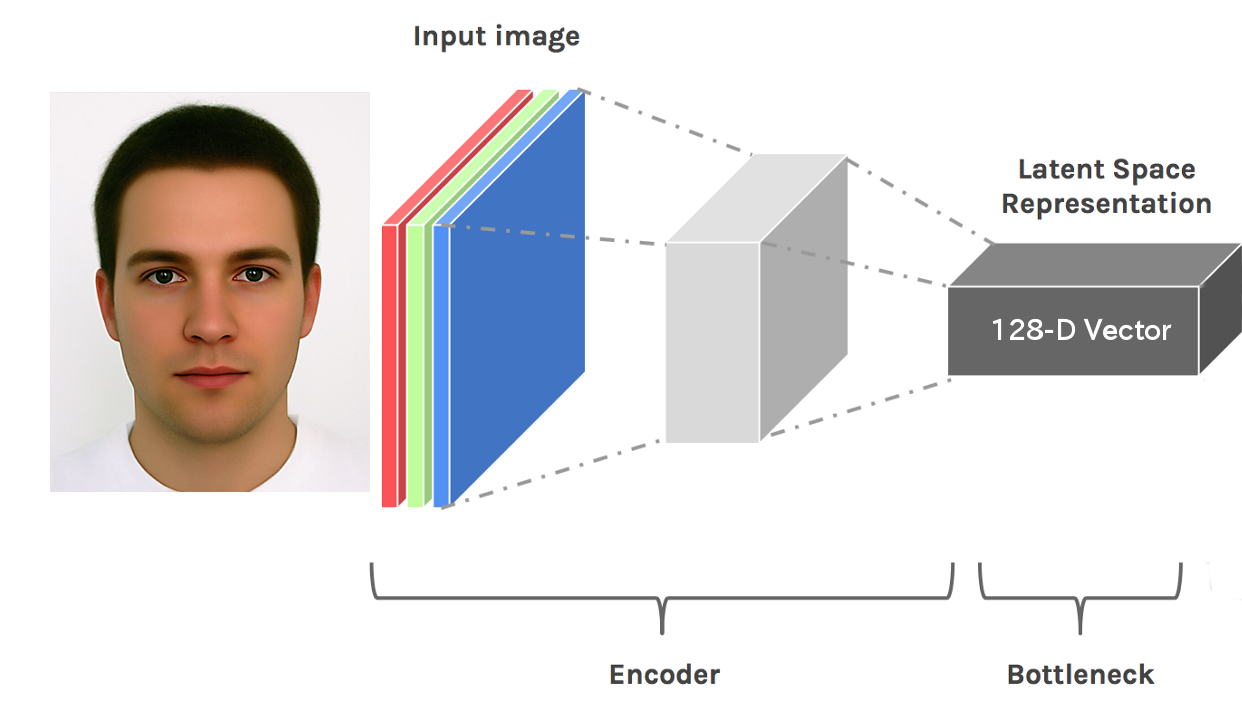
Pixel data is encoded to 128 dimensional vector
This is called the latent-space representation of the face. The mathematical nature of the vectors in this space is such that similar faces will have vectors close to each other (smaller euclidean distance) and different faces will be located far apart. These facial vectors are called face embeddings.
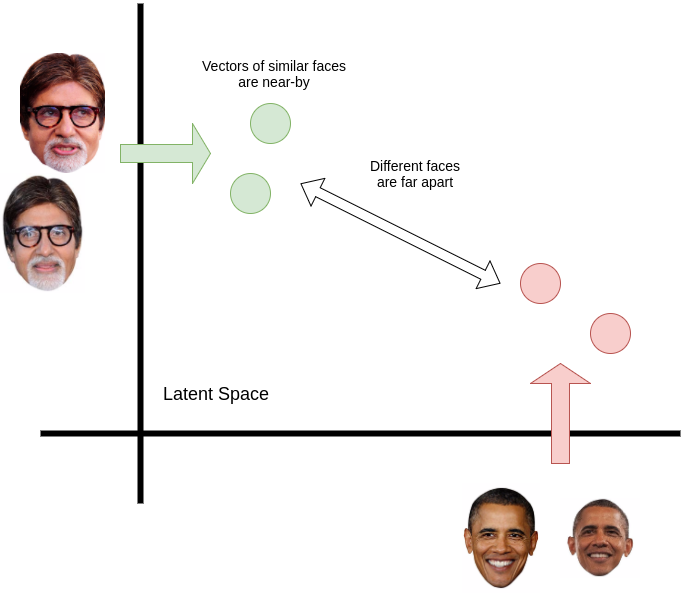
Similar faces end up closer to each other and different faces are far apart in the latent space
In trivial cases, matching faces is simply a matter of calculating euclidean distances and checking against a threshold. If the vectors are farther than a specific threshold, it can safely be assumed that these must belong to different faces. In production systems though, size of the face database determines how face matching is performed. For systems with thousand to ten thousand faces, a secondary classifier is trained on the face embeddings. This can be a k-d tree or an SVM classifier. For larger systems with millions of faces, algorithms such as LVQ and its variations are employed. The matching of face embeddings is a separate topic and will be addressed in a different article.

